两个好用到爆的Python模块 轻松解决烦恼的匹配问题
 大怪科学
大怪科学
在日常开发工作中,经常会遇到这样的一个问题:要对数据中的某个字段进行匹配,但这个字段有可能会有微小的差异。比如同样是招聘岗位的数据,里面省份一栏有的写“广西”,有的写“广西壮族自治区”,甚至还有写“广西省”……为此不得不增加许多代码来处理这些情况。
今天跟大家分享FuzzyWuzzy一个简单易用的模糊字符串匹配工具包。让你轻松解决烦恼的匹配问题!
前言
在处理数据的过程中,难免会遇到下面类似的场景,自己手里头获得的是简化版的数据字段,但是要比对的或者要合并的却是完整版的数据(有时候也会反过来)
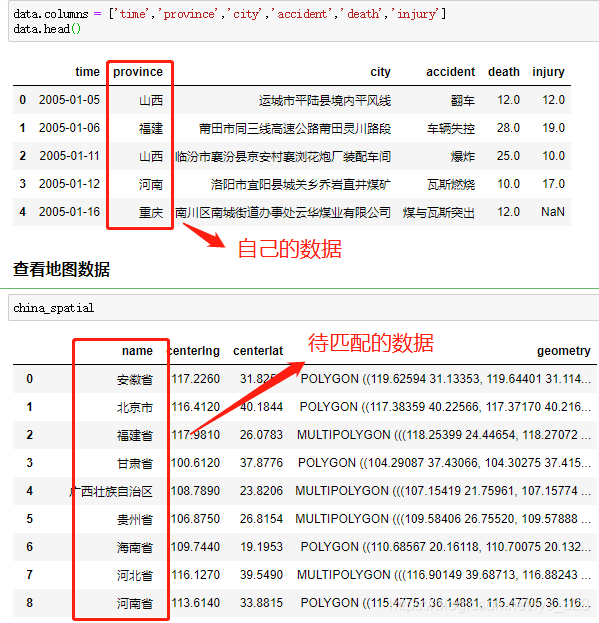
最常见的一个例子就是:在进行地理可视化中,自己收集的数据只保留的缩写,比如北京,广西,新疆,西藏等,但是待匹配的字段数据却是北京市,广西壮族自治区,新疆维吾尔自治区,西藏自治区等,如下。
因此就需要有没有一种方式可以很快速便捷的直接进行对应字段的匹配并将结果单独生成一列,就可以用到FuzzyWuzzy库。
FuzzyWuzzy库介绍
FuzzyWuzzy 是一个简单易用的模糊字符串匹配工具包。它依据 Levenshtein Distance 算法,计算两个序列之间的差异。
Levenshtein Distance 算法,又叫 Edit Distance 算法,是指两个字符串之间,由一个转成另一个所需的最少编辑操作次数。许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
这里使用的是Anaconda下的jupyter notebook编程环境,因此在Anaconda的命令行中输入一下指令进行第三方库安装。
1 fuzz模块
该模块下主要介绍四个函数(方法),分别为:简单匹配(Ratio)、非完全匹配(Partial Ratio)、忽略顺序匹配(Token Sort Ratio)和去重子集匹配(Token Set Ratio)
注意:如果直接导入这个模块的话,系统会提示warning,当然这不代表报错,程序依旧可以运行(使用的默认算法,执行速度较慢),可以按照系统的提示安装python-Levenshtein库进行辅助,这有利于提高计算的速度。

1.1 简单匹配(Ratio)
简单的了解一下就行,这个不怎么精确,也不常用
fuzz.ratio("河南省","河南省")
output
100
fuzz.ratio("河南","河南省")
output
80
1.2 非完全匹配(Partial Ratio)
尽量使用非完全匹配,精度较高
fuzz.partial_ratio("河南省","河南省")
output
100
fuzz.partial_ratio("河南","河南省")
output
100
1.3 忽略顺序匹配(Token Sort Ratio)
原理在于:以 空格 为分隔符,小写 化所有字母,无视空格外的其它标点符号
fuzz.ratio("西藏自治区","自治区西藏")
output
50
fuzz.ratio('IloveYOU','YOULOVEI')
output
30
fuzz.token_sort_ratio("西藏自治区","自治区西藏")
output
100
fuzz.token_sort_ratio('IloveYOU','YOULOVEI')
output
100
1.4 去重子集匹配(Token Set Ratio)
相当于比对之前有一个集合去重的过程,注意最后两个,可理解为该方法是在token_sort_ratio方法的基础上添加了集合去重的功能,下面三个匹配的都是倒序
fuzz.ratio("西藏西藏自治区","自治区西藏")
output
40
fuzz.token_sort_ratio("西藏西藏自治区","自治区西藏")
output
80
fuzz.token_set_ratio("西藏西藏自治区","自治区西藏")
output
100
fuzz这几个ratio()函数(方法)最后得到的结果都是数字,如果需要获得匹配度最高的字符串结果,还需要依旧自己的数据类型选择不同的函数,然后再进行结果提取,如果但看文本数据的匹配程度使用这种方式是可以量化的,但是对于我们要提取匹配的结果来说就不是很方便了,因此就有了process模块。
process模块
用于处理备选答案有限的情况,返回模糊匹配的字符串和相似度。
2.1 extract提取多条数据
类似于爬虫中select,返回的是列表,其中会包含很多匹配的数据
choices=["河南省","郑州市","湖北省","武汉市"]
process.extract("郑州",choices,limit=2)
output
[('郑州市',90),('河南省',0)]
extract之后的数据类型是列表,即使limit=1,最后还是列表,注意和下面extractOne的区别
2.2extractOne提取一条数据
如果要提取匹配度最大的结果,可以使用extractOne,注意这里返回的是 元组 类型, 还有就是匹配度最大的结果不一定是我们想要的数据,可以通过下面的示例和两个实战应用体会一下
process.extractOne("郑州",choices)
output
('郑州市',90)
process.extractOne("北京",choices)
output
('湖北省',45)
3. 实战应用
这里举两个实战应用的小例子,第一个是公司名称字段的模糊匹配,第二个是省市字段的模糊匹配
3.1 公司名称字段模糊匹配
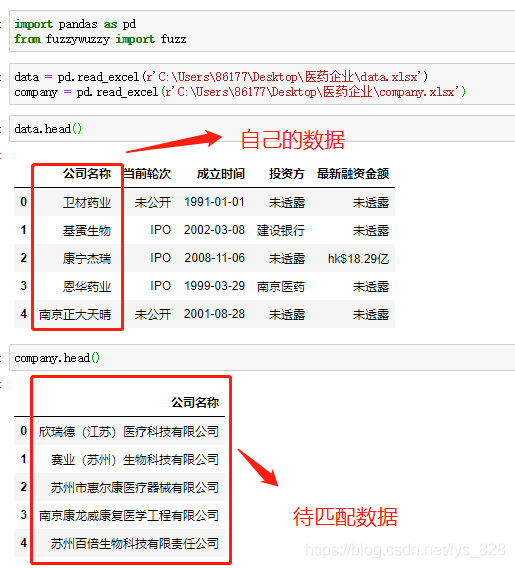
数据及待匹配的数据样式如下:自己获取到的数据字段的名称很简洁,并不是公司的全称,因此需要进行两个字段的合并
直接将代码封装为函数,主要是为了方便日后的调用,这里参数设置的比较详细,执行结果如下:
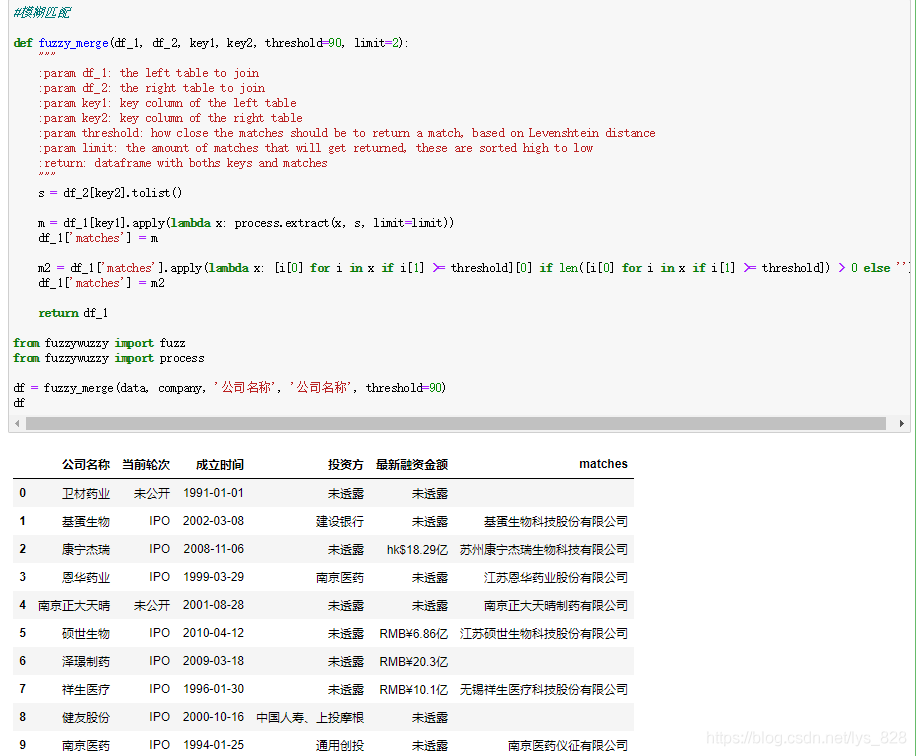
3.1.1参数讲解
第一个参数df_1是自己获取的欲合并的左侧数据(这里是data变量);
第二个参数df_2是待匹配的欲合并的右侧数据(这里是company变量);
第三个参数key1是df_1中要处理的字段名称(这里是data变量里的‘公司名称’字段)
第四个参数key2是df_2中要匹配的字段名称(这里是company变量里的‘公司名称’字段)
第五个参数threshold是设定提取结果匹配度的标准。注意这里就是对extractOne方法的完善,提取到的最大匹配度的结果并不一定是我们需要的,所以需要设定一个阈值来评判,这个值就为90,只有是大于等于90,这个匹配结果我们才可以接受
第六个参数,默认参数就是只返回两个匹配成功的结果
返回值:为df_1添加‘matches’字段后的新的DataFrame数据
3.1.2 核心代码讲解
第一部分代码如下,可以参考上面讲解process.extract方法,这里就是直接使用,所以返回的结果m就是列表中嵌套元祖的数据格式,样式为: [(‘郑州市’, 90), (‘河南省’, 0)],因此第一次写入到’matches’字段中的数据也就是这种格式
注意,注意:元祖中的第一个是匹配成功的字符串,第二个就是设置的threshold参数比对的数字对象
s=df_2[key2].tolist()
m=df_1[key1].apply(lambdax:process.extract(x,s,limit=limit))
df_1['matches']=m
第二部分的核心代码如下,有了上面的梳理,明确了‘matches’字段中的数据类型,然后就是进行数据的提取了,需要处理的部分有两点需要注意的:
提取匹配成功的字符串,并对阈值小于90的数据填充空值
最后把数据添加到‘matches’字段
m2=df_1['matches'].apply(lambdax:[i[0]foriinxifi[1]>=threshold][0]iflen([i[0]foriinxifi[1]>=threshold])>0else'')
#要理解第一个‘matches’字段返回的数据类型是什么样子的,就不难理解这行代码了
#参考一下这个格式:[('郑州市', 90), ('河南省', 0)]
df_1['matches']=m2
returndf_1
3.2 省份字段模糊匹配
自己的数据和待匹配的数据背景介绍中已经有图片显示了,上面也已经封装了模糊匹配的函数,这里直接调用上面的函数,输入相应的参数即可,代码以及执行结果如下:
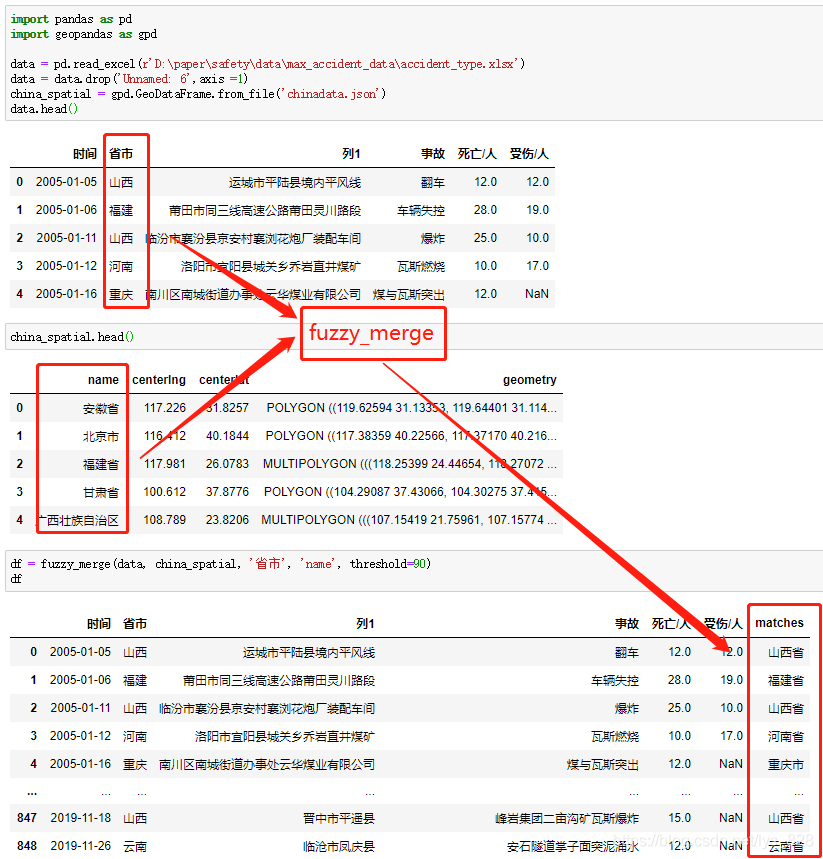
数据处理完成,经过封装后的函数可以直接放在自己自定义的模块名文件下面,以后可以方便直接导入函数名即可,可以参考将自定义常用的一些函数封装成可以直接调用的模块方法。
4. 全部函数代码
#模糊匹配
deffuzzy_merge(df_1,df_2,key1,key2,threshold=90,limit=2):
"""
:paramdf_1:thelefttabletojoin
:paramdf_2:therighttabletojoin
:paramkey1:keycolumnofthelefttable
:paramkey2:keycolumnoftherighttable
:paramthreshold:howclosethematchesshouldbetoreturnamatch,basedonLevenshteindistance
:paramlimit:theamountofmatchesthatwillgetreturned,thesearesortedhightolow
dataframewithbothskeysandmatches
"""
s=df_2[key2].tolist()
m=df_1[key1].apply(lambdax:process.extract(x,s,limit=limit))
df_1['matches']=m
m2=df_1['matches'].apply(lambdax:[i[0]foriinxifi[1]>=threshold][0]iflen([i[0]foriinxifi[1]>=threshold])>0else'')
df_1['matches']=m2
returndf_1
fromfuzzywuzzyimportfuzz
fromfuzzywuzzyimportprocess
df=fuzzy_merge(data,company,'公司名称','公司名称',threshold=90)
df
审核编辑:刘清
查看全文



评论0条评论